今天我們來使用TF 2.0來實作VGG 16,那為什麼選擇VGG 16呢?雖然VGG 16並未拿下當年ILSVRC 的分類比賽的冠軍 (當年由Google所發明的Inception拿到冠軍),但他開啟了使用較小filter為主流的CNN模型。而VGG模型架構簡單好理解 雖然模型參數超級多。接下來會稍微簡單的說明VGG。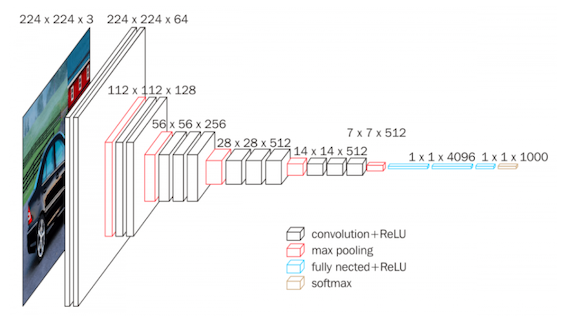
source
VGG最重要的概念就是大量使用3X3的Conv layers、較小的stride (strides=1)以及Pooling (2X2),論文作者認為較小的Con layers可以提高所得到的資訊量。此外,相對於Alexnet所使用的7X7 Conv layers,3X3的Cony layers也有較高的Non-linearity。此外,VGG也證明了Deeper > shallow!透過較小的filter所疊出來的架構仍然能繼續提高Accuracy。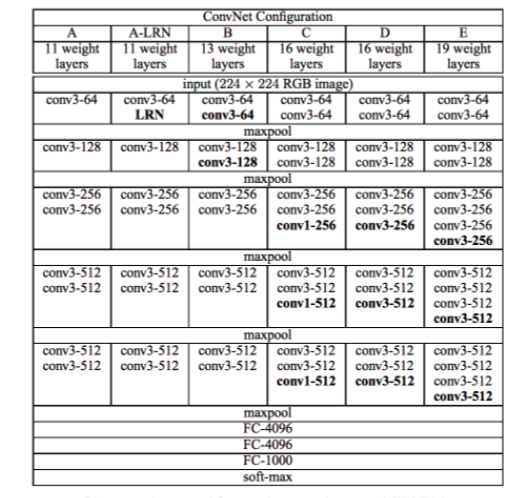
針對Benchmark來看,VGG相對於於過去重大幅提升以及運算時間大幅提升,但對於一個最簡單(single crop)以及層數之間的比較,預測效果相較於AlexNet 、Inception來說均有較好的準確度。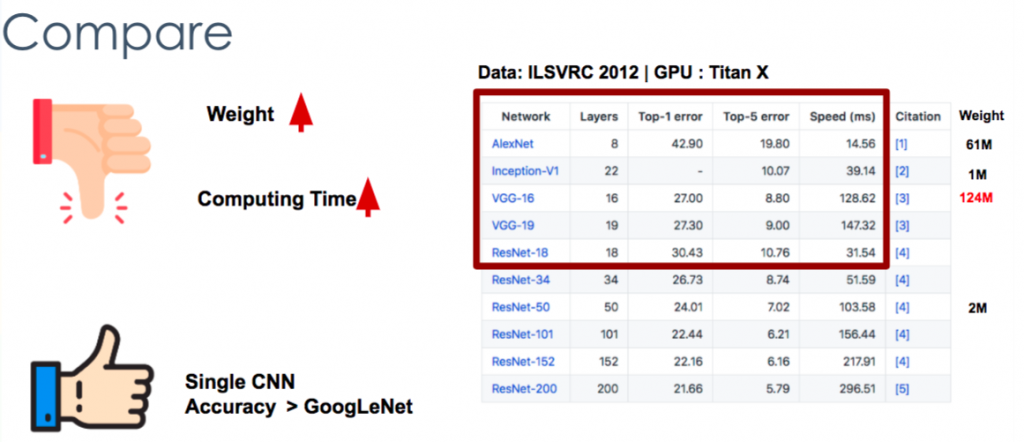
source
接下來我們來簡單實作CNN - VGG的模型(C),這次使用的資料是CIFAR 10,CIFAR 10是由 Alex Krizhevsky、Ilya Sutskever 所release出來的資料集。 資料筆數約 6萬筆,每張圖為 32*32 解析度的彩色圖片, 其中 5 萬筆為訓練集; 1 萬筆為測試集 ,為影像辨識常使用的資料及之一。
首先,可以直接使用TF的api來下載資料
(x,y),(x_test,y_test) = datasets.cifar10.load_data()
接下來我們可以簡單來畫圖,看一下圖片長什麼樣子
plt.figure()
plt.imshow(x[0])
plt.colorbar()
plt.grid(False)
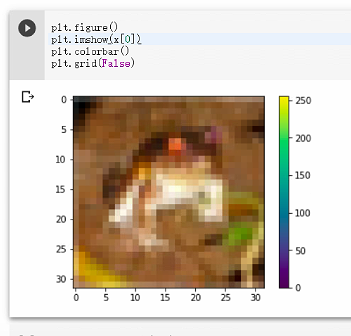
我猜這是一隻青蛙吧XD
接下來是比較重點的部分,我們要架兩個part的模型架構,分為CNN part跟後面Fully Conneted part,可以看以下的架構。
vgg_layers = [
#stack1
layers.Conv2D(64,kernel_size=[3,3],padding='same',activation=tf.nn.relu), layers.Conv2D(64,kernel_size=[3,3],padding='same',activation=tf.nn.relu), layers.MaxPool2D(pool_size=[2,2],strides=2,padding='same'),
#stack2
layers.Conv2D(128,kernel_size=[3,3],padding='same',activation=tf.nn.relu), layers.Conv2D(128,kernel_size=[3,3],padding='same',activation=tf.nn.relu), layers.MaxPool2D(pool_size=[2,2],strides=2,padding='same'),
#stack3
layers.Conv2D(256,kernel_size=[3,3],padding='same',activation=tf.nn.relu), layers.Conv2D(256,kernel_size=[3,3],padding='same',activation=tf.nn.relu), layers.Conv2D(256,kernel_size=[1,1],padding='same',activation=tf.nn.relu), layers.MaxPool2D(pool_size=[2,2],strides=2,padding='same'),
#stack4
layers.Conv2D(512,kernel_size=[3,3],padding='same',activation=tf.nn.relu), layers.Conv2D(512,kernel_size=[3,3],padding='same',activation=tf.nn.relu), layers.Conv2D(512,kernel_size=[1,1],padding='same',activation=tf.nn.relu), layers.MaxPool2D(pool_size=[2,2],strides=2,padding='same'),
#stack5
layers.Conv2D(512,kernel_size=[3,3],padding='same',activation=tf.nn.relu), layers.Conv2D(512,kernel_size=[3,3],padding='same',activation=tf.nn.relu), layers.Conv2D(512,kernel_size=[1,1],padding='same',activation=tf.nn.relu), layers.MaxPool2D(pool_size=[2,2],strides=2,padding='same')]
fc_layers =[
layers.Dense(256,activation=tf.nn.relu),
layers.Dense(256,activation=tf.nn.relu),
layers.Dense(100,activation=None)]
接下來就可以直接Compile!其他資料處理的步驟跟DNN之前的很像
vgg = Sequential(vgg_layers)
vgg.build(input_shape=[None,32,32,3])
fc = Sequential(fc_layers)
fc.build(input_shape=[None,512])
optimizer = optimizers.Adam(lr=1e-4)
在train跟update的部分,記得要把variable放在一起利用計算好的loss來update網路!
variables = vgg.variables + fc.variables
for i in range(5):
for step,(x,y) in enumerate(data):
with tf.GradientTape() as tape:
logits = vgg(x)
logits = tf.reshape(logits,[-1,512])
logits = fc(logits)
y_one_hot = tf.one_hot(y,depth=10)
loss = tf.losses.categorical_crossentropy(y_one_hot,logits,from_logits=True)
loss = tf.reduce_mean(loss)
grads = tape.gradient(loss,variables)
optimizer.apply_gradients(zip(grads,variables))
而最後test跟valid的步驟跟train的部分非常接近,有附上colab可以試試看。但在Colab上跑VGG不開GPU train真的超級慢,因此大家記得把Colab的GPU開起來train Model測試~
VGG的參數量真的有點多,就在寫完的當下也放颱風假了,明天可以繼續拼一下文章。感謝大家漫長的閱讀~~


